

The rise of powerful, data-driven machine learning methods has broadened the possibilities for implementing AI in a wide range of real-world applications, including self-driving vehicles, medical diagnosis, intelligent educational support, industrial quality assurance, or supply chain management. However, for practical applications, AI systems have to be trustworthy AI systems: safe, robust, transparent, and corrigible.
Taking a step back: Why do software systems need to be trustworthy?
Let’s begin by examining standard software systems without AI components. The rule of thumb when designing software is: The more complex the system, the more difficult it can be to control its behavior. The program code of standard software is usually entirely inspectable, enabling human comprehension and evaluation. Furthermore, most of the code in safety-critical applications is deterministic, ensuring that the input-output behavior is predictable regardless of the environment or conditions in which it is executed. The software’s behavior can be systematically tested and – more important for safety critical code –, it can be formally proven that the code fulfills specific requirements. For instance, in the case of an airbag controller, it is necessary to demonstrate that the code is complete and correct, ensuring the airbag deploys only when necessary and not in any other circumstances.
Why use AI systems in the first place?
AI systems broaden the range of functionalities beyond those of deterministic software systems. They are primarily implemented for three reasons:
- Complex Problems: AI systems are used when a problem is too complex for traditional algorithms to efficiently compute. Heuristic algorithms are employed to approximate a solution, although it cannot be guaranteed that the solution is optimal or that it even exists. Typical examples are scheduling and routing problems.
- Complex Domain Knowledge: AI systems are needed when the problem at hand involves complex domain knowledge and inferences that go beyond the capabilities of standard data structures and algorithms. Typical examples are ontological reasoning and action planning, for instance when generating treatment plans or recommending medical interventions. Here, knowledge about specific medical domains, medical guidelines, and patient data can be represented in logic-based knowledge representation languages.
- Implicit Knowledge: AI methods, specifically machine learning, become necessary when the given problem cannot be specified explicitly. This is the case for most of perceptual knowledge, such as the implicit knowledge behind recognizing a cat in an image, identifying a skin change as melanoma, or evaluating the quality of a welding joint. In these cases, machine learning algorithms can be used to learn patterns and to infer a model from training data. In the next step, this model can be applied to new instances and make accurate predictions or classifications.
However, unlike standard software, there is no guarantee of completeness and correctness for AI systems. This can be particularly challenging for users and add an additional layer of complexity to navigate when using AI systems – especially because it may not always be apparent or transparent that the solution provided by the AI system is incomplete or incorrect.

Inside the black box
The most powerful machine learning approaches involve complex neural architectures, known as deep learning approaches. Convolutional Neural Networks (CNNs) are particularly effective for image classification. However, the resulting models are black boxes: The input goes through complex mathematical operations, making it difficult to interpret how the model generates its output. The black box nature of CNNs and the interpretability of their output can become a concern, particularly when the application demands a high level of accuracy and reliability.
How high the demand for accuracy and reliability is, depends on the application domain. In certain domains, such as image retrieval, it may be acceptable to have less than 100 % perfect accuracy. For example, if you search for an image of a cat lying on a sofa, it is reasonable that only some of the top ten images meet your criteria. Humans can easily select a suitable output and discard unsuitable ones based on their intuition. However, this may not necessarily be the case in highly specialized application domains, such as image based medical diagnosis or industrial quality control. In these specialized domains, the accuracy and reliability of the model’s output are of paramount importance. Black box models may not provide the necessary transparency or explainability required for these critical applications.
Issues of machine learned models: What is sampling bias, overfitting, and the Clever Hans effect?
One of the most critical factors determining the quality of a learned model is the quality of the training data. Supervised machine learning algorithms require a sufficient amount of labeled data, representing the ground truth. Often, the task of labeling training data is outsourced to non-expert click workers. However, for highly specialized domains like medicine or industry, it might be necessary to involve domain experts, such as a pathologist, or an industrial quality engineer. This, naturally, increases the cost of obtaining high-quality data sets.
In various application scenarios, providing precise ground truth labels can be challenging or even impossible. While humans can easily agree on labels for traffic signs or for images of husky versus wolf, there are more complex domains where experts may disagree on how to label certain images. For example, when characterizing tumors with biomarkers, in medical diagnosis, or when labeling facial expressions, the ascriptions can be subjective and open to interpretation (see also Slany et al. 2022).
Moreover, the quality of training data can be compromised when it reflects discriminations of specific subgroups, such that gender or ethnicity, leading to correlations with predictions like health risk or creditworthiness. Another problem with respect to data quality arises when the data sampling is not representative and crucial variations in the natural distribution are either not present or underrepresented. This can create a sampling bias in the training data which are reproduced in real-word applications (read more on the issue in our Affective Computing 101). Another issue are imbalanced class distributions where, as a consequence and without further augmentation, the dominant class might be favored by the learned classifier. Additionally, irrelevant features that correlate with the predicted class in the sampled data can lead to incorrect class decisions. A prominent example is the classification of wolf versus husky depending on the background color.
Technically, the described problem is characterized as overfitting. Overfitted models (also known as Clever Hans models) rely on patterns present in the training data but not representative of the natural distribution, failing to generalize to the broader data distribution. The “Clever Hans” phenomenon refers to a horse named Hans that was exhibited at Berlin fairs in the 1920s and believed to be capable of performing addition of natural numbers by nodding its head in accordance with the sum. However, it was later revealed that the horse was actually reacting to subtle signals given by its owner, rather than actually understanding the mathematical operation.
In sum, despite the effort of researchers and users in providing high-quality data sets, there is no guarantee that the learned model will perform consistently well for all inputs. Therefore, machine learning applications must be augmented with additional methods to ensure their reliability and trustworthiness.
What are the requirements for AI systems to be trustworthy?
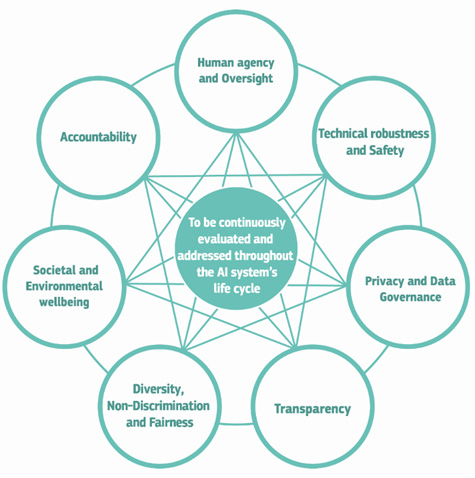
The European Commission proposed an ethics guideline for trustworthy AI, identifying several requirements including safety, robustness, transparency, corrigibility (human agency and oversight) as well as diversity and inclusiveness (design for all), fairness (non-discrimination), privacy and data governance, and societal and environmental well-being.
Some of these requirements can be addressed by following procedures and applying methods defined in computer science in general, such as privacy, design for all, and to some degree safety. Other requirements involve ethical and legal standards as well as general political goals, namely fairness and societal and environmental well-being. Most of these requirements demand to extend and augment purely data-driven machine learning with methods from knowledge-based AI and human-computer-interaction. The combination of machine learning and knowledge-based technologies is called hybrid AI.
How can hybrid AI support trustworthiness?
Hybrid AI refers to the combination of data-driven and knowledge-based AI approaches. It involves both detecting complex patterns in data and utilizing pre-defined domain knowledge. While humans learn increasingly complex concepts and skills by building on previous knowledge, standard machine learning learns everything from scratch repeatedly. By incorporating prior knowledge (e.g., from textbooks or manuals) into the machine learning process, the need for extensive training data is reduced, meaning less annotation effort and energy savings for storage and processing.
From black box to white box: How can explainable and interactive machine learning support trustworthiness?
Transparency requirements can be met by using interpretable machine learning approaches, such as decision trees or inductive logic programming (ILP). These white box approaches represent models with symbolic rules, making them examinable like conventional program code. However, for domains such as image classification, these types of machine learning are not suitable. In these cases of black box machine learning, transparency can be addressed by applying methods of explainable AI (XAI). XAI methods help understand why a black box model produces a specific output. Such local explanations can be generated by model agnostic or model specific methods. Well-known model agnostic methods are LIME, SHAP, and RISE, all of them helping to identify which parts of the input had the most impact on the model output.
Finally, interactive machine learning, also known as human-in-the-loop learning, allows end users or domain experts to correct and refine model outputs. For effective correction, it is important for the human agent to comprehend why the model produced a given output. Therefore, XAI and interactive learning methods have been combined to develop approaches for explanatory interactive machine learning (see, for instance, FairCaipi).
Image copyright: iStock






Add comment