
Back in August 2019, we published a post called ‘Per-Title-Encoding’, shortly followed by ‘Calculating VMAF and PSNR with FFmpeg’.
To pick up where we left off, we’d like to begin a “Deep Encode” series – a sequence of blog posts covering a project called ‘FAMIUM Deep Encode’. FAMIUM Deep Encode is a long-term research and development project in which we’ve developed an AI-supported per-title encoding architecture. In other words, improve the per-title encoding process with a bunch of machine learning models.
In this series, we will cover different aspects of the project: architecture components (part 2), machine learning (part 3) and production encoding (part 4). For each aspect, we will discuss its current development, issues we’ve faced and concepts we’d like to explore in the future.
For this particular article, we will discuss how this project came to be, provide an overview of our project components, and per-scene encoding.
Overview
So, why an AI-supported solution for per-title encoding?
Well, as you’ve seen from the first and second blog posts, the entire per-title encoding workflow can become complex in producing a sufficient amount of test encodes needed in order to produce sufficient data for an optimal encoding ladder. As a result, this process becomes time consuming, a high amount of storage is used, etc.
As you can see, not an ideal solution for a team of engineers, much less a video encoding enthusiast.
What do we do?
Two words: MACHINE. LEARNING. (Which will be covered in more detail in the next two posts!)
What if: we developed a solution that can produce virtual encodes (total time-saver), send those encodes to a few machine learning models (since machine learning is all the rage these days), and spit out an optimal encoding ladder. And to put a cherry on top, generate production encodes from the encoding ladder. Neat, right?
Admittedly, this project consisted a lot of trial-and-error, from finetuning our models, to increasing the speed of the video analysis. Nevertheless, the ongoing process has been quite fascinating, and proved to be full of potential (a.k.a, a long laundry list of ideas).
What’s been happening?
Up until now, we’ve developed that aforementioned ‘what if’, and knee-deep in optimizing the workflow architecture:
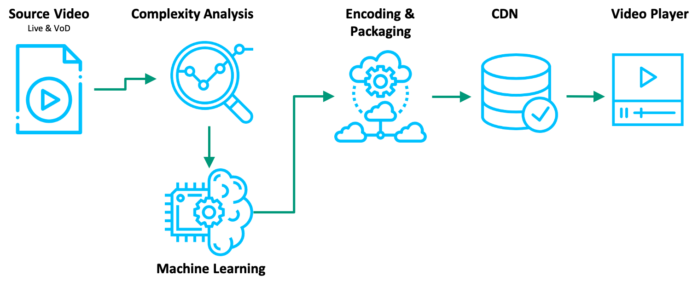
We have a handy and interactive UI that supports the architecture, so that interested customers can log in and encode their own videos. This technology remains codec-agnostic, although we are exploring each codec individually in order to create THE technology.
There’s an entire complexity analysis component made up of workers and API’s (developed in JS and Python) that analyzes the source video in order to create the virtual encodes. This part was a cool way to really dive deep into the field of computer vision and explore different algorithms that can best represent the complexity of a video. As part of the complexity analysis, we have several workers running hot with: scene detection, general metadata extraction, SI/TI algorithms, classification, etc. This will be covered in more detail in the next post.
Then, we have five machine learning models: Feed Forward Fast Connect, XGBoost, Convolutional Neural Networks, and 2 types of Stacked Models. And yes, they all predict an optimal encoding ladder. However, we’ve discovered that due to the architecture of each machine learning model, the results were quite different from one another. For purposes of comparison, we’ve continuously optimized all five models in order to find the ‘ideal’ algorithm. Our machine learning component will be covered in more detail in part 3 of this series.
Finally, we have a production encoding feature – where you can select the type of encoding you want, fiddle around with the encoding settings, check its actual quality (VMAF), and download the encode to be played in any media player.
What’s in store for the future? Per-scene encoding!
Per-scene encoding is where individual scenes within an entire video are encoded, rather than encoding the entire video with an optimal encoding ladder.

With this process, bitrates can be saved even further, and multiple encoding ladders would be produced per scene, meaning, individual scenes that require lower (or sometimes higher) bitrates than others would be encoded as such, thereby improving the overall quality of the video.
How is this possible? As with the concept of per-title encoding, certain scenes within a video are more/less complex than others, and would require different bitrate values for sufficient quality.
To test this concept, we took a 30-second sports clip at 1080p (high amount of movement with high redundancy), ran it through our scene change detector, complexity analysis, and machine learning model. In the table below, one scene with high redundancy and low movement (the opening scene) only required 1141 kb/s, while another scene with low redundancy and a high amount of movement required a higher bitrate of of 3316 kb/s at 1080p, both achieving the same predicted VMAF quality of 90.

As part of the per-scene encoding workflow, the scenes were stitched together to analyze the overall file size, bitrate, and VMAF quality, which resulted in 11mb, 2427kbps and 90, respectively. In comparison to the per-title encoding method, at 1080p, the overall file size, bitrate and VMAF resulted in 13.72mb, 3111kbps and 90, respectively. Based on these preliminary results, it can be assumed that both file size and bitrate values can be saved using the per-scene encoding method instead.
To make this process ‘AI-supported’, the entire architecture would be updated so that multiple virtual encodes per scene are fed to the machine learning models, producing several several encoding ladders for one video:
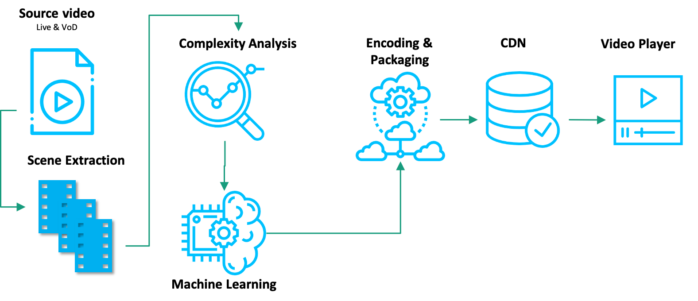
As you can see in the workflow diagram, in comparison to the previous per-title workflow, there is an additional step prior to the ‘Complexity Analysis’. Here, a scene change detector extracts scenes from the source video based on scene changes (black outs, frame fades, etc.) and a predetermined threshold. (As a side note: the ‘threshold’ is a factor that influences the number of scenes that are extracted.) The extracted scenes are then analyzed in terms of complexity, and its results are sent to the machine learning model.
In other words, it’s as if per-title-encoding got bit by a radioactive spider. #notsponsoredbymarvel
Conclusion
In this post, we’ve introduced our Deep Encode project, touched upon vital components that we’ve developed, and discussed the concept of per-scene encoding. Special thanks to my fellow colleagues, Neel and Tu, for their contributions to this post.
Stay tuned for Part 2 of this series, where we dive deep into the development of video complexity!
If you have any questions in regards to our Deep Encode activities, please check out our website.