Overview
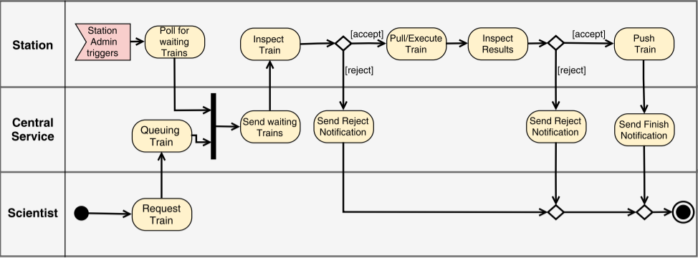
Stations are the nodes in the distributed architecture that hold the confidential data and execute analytic tasks. Each Station is registered in a Station Registry and acts as an autonomous and independent unit. In the distributed architecture, the communication is designed to be one-way, i.e., Stations are actively polling the CS if there are Train requests waiting to be executed. In contrast, the CS does not have an active channel to the Station such that the Station admins or curators of privacy-sensitive data have at any time the high-level sovereignty of any activities affecting the corresponding Station. Our four communication commands are:
- Poll for new Trains
- Pull a Train from the repository
- Reject a Train from the repository
- Push a Train back to the repository
A workflow, which explains the activities in more detail, is given in the following picture.
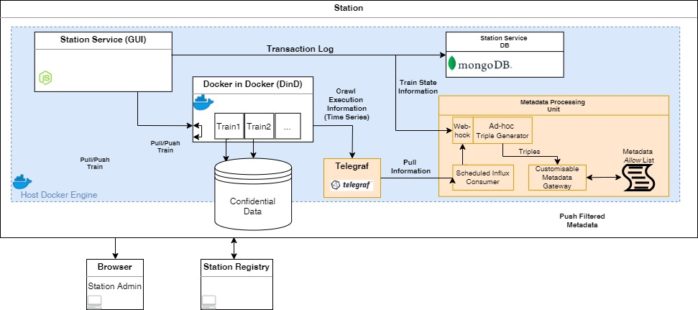
The Station has two main components: The data source and the Station Software. The Station can hold the data itself or provides an access point to the sensitive data. The main task of the Stations is the execution of the containerised analytic algorithms (Trains). Therefore, every Station communicates with a local Docker engine to execute a Train. This execution consists of five steps, i.e., pulling image from Train Registry to the local machine, creating and starting the container of the corresponding pulled Train image, committing the container to create a new image from the container’s changes, and pushing the changed image back to the Train Repository. Furthermore, since the data providers or institutions could have different authentication procedures, we do not restrict the Station software to one single authentication technology and leave the integration of the authentication mechanism to the institution.
In addition, each Station provides a graphical user interface representing a management console to coordinate the Train execution cycle (For more information have a look into our Train Creation Wizard).
Components

Our Trains are executed in a Docker in Docker Container, which runs on the Host Docker Engine. This has the advantage that the Trains have their own sandbox and do not interfere with the containers on the Host engine.
We use a mongoDB container to store transaction logs, which can be reused for debugging purposes.

In order to store Station-related and sensitive data/credentials, we use a Vault container. Vault can easily be configured by our Station GUI and facilitates the Train execution process via an easy-to-use interface.