The PHT originates from an analogy from the real world. The infrastructure reminds of a railway system including trains, stations, and train depots. The train uses the network to visit different stations to transport, e.g., several goods.
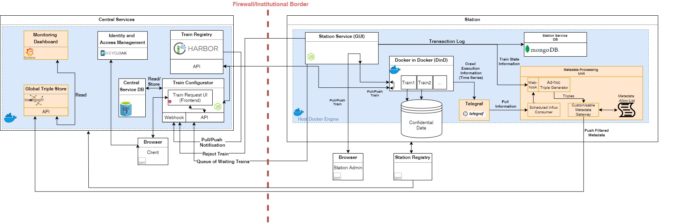
Adapting this concept to the PHT ecosystem, we can draw the following similarities. The Train encapsulates an analytical task, which is represented by the good in the analogy. The data provider takes over the role of a reachable Station, which can be accessed by the Train. Further, the Station executes the task, which processes the available data. The depot is represented by our Central Service (CS) including procedures for Train orchestration, operational logic, business logic, and data management. The goal of this design paradigm is to bring the algorithm to the data instead of bringing confidential data to the algorithm, which enables the compliance to data protection requirements.
Furthermore, we pay attention to the following design aspects. Every component of our architecture is containerised using the Docker technology to facilitate software development. In addition, the components are loosely coupled to enable possible extensions and (REST API) web service orchestration. For improved usability, each node is accessible via a browser.