

Anwendung von Machine Learning Verfahren trotz geringer Datenbasis
In der hier angekündigten Podcastfolge spreche ich mit Dr. Christian Menden über die Methoden und Anwendungsmöglichkeiten seiner Kompetenzsäule »Few Data Learning«.
In dieser Kompetenzsäule geht es darum, eine kleine oder qualitativ unzureichende Datenbasis anzureichern, damit trotzdem Machine Learning Verfahren eingesetzt werden können. »Few Data Learning« beschäftigt sich also damit, Daten für KI-Verfahren überhaupt erst nutzbar zu machen.
Was ist Few Data Learning?
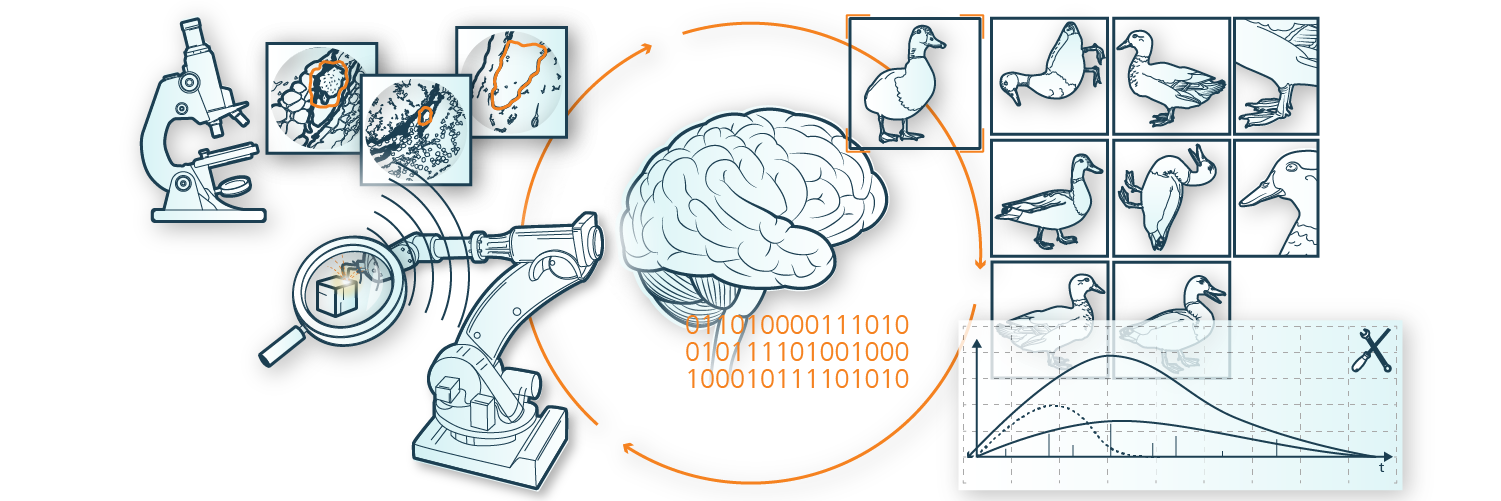
Ein wichtiger Baustein für Machine Learning-Verfahren ist das Vorhandensein einer großen Menge von qualitativ hochwertigen Daten. In der Praxis gibt es allerdings Fälle, in denen einfach nicht genügend Daten vorhanden sind oder es viele fehlerhafte Daten gibt, wenn beispielsweise in einer Fertigung einzelne Sensoren ausfallen oder Anlagen auf ein neues Produkt umgerüstet werden. In manchen Anwendungsbereichen ist es auch einfach so, dass die Annotation und Strukturierung von Daten sehr aufwändig ist und nicht vollautomatisiert möglich ist, wie bei Gewebescans im medizinischen Bereich.
Unterschiedliche Verfahren für unzureichende Datensätze
In verschiedenen Verfahren können Datensätze angereichert werden. Fehlen in einem Datensatz einige wenige Daten Punkte, werden Lücken im Imputations-Verfahren gefüllt.
Sind die Lücken aber größer und substantiell, werden die wenigen vorhandenen Daten genutzt und nach Mustern gesucht, um zusätzliche Daten zu generieren. Sind gar keine Daten vorhanden, können Simulationstechniken eingesetzt werden, um Datensätze zu generieren.
Die Einsatzmöglichkeiten in unterschiedlichsten Bereichen ist riesig: von der Qualitätskontrolle von Produkten, Umrüstung einer bestehenden Fertigung für ein neues Produkt, bis hin zur bildgestützten Diagnose von Darmkrebsregionen.
Welche Methoden in welcher Anwendung eingesetzt werden und was Few Data Learning mit Few Labels Learning zu tun hat, verrät Ihnen Christian in der neuen Folge!
Using machine learning methods despite a small database
In this podcast episode I talk with Dr. Christian Menden about the methods and possible applications of his competence pillar Few Data Learning.
This competence pillar is about enriching a small or qualitatively insufficient data base so that Machine Learning methods can still be used. “Few Data Learning” is therefore a research area that deals with making data usable for AI procedures
What is Few Data Learning?
An important foundation for machine learning methods is the presence of a large amount of high-quality data. In practice, there are cases where there simply isn’t enough data or there is a lot of erroneous data, such as when individual sensors fail in a manufacturing facility or equipment is being converted to create a new product. In some application areas, it is also simply the case that the annotation and structuring of data is very time-consuming and cannot be fully automated, as in the case of tissue scans in the medical field.
Different procedures for insufficient data sets
Data sets can be enriched in different procedures:
– a few data points are missing in a data set, gaps are filled using the imputation procedure
– the gaps are larger and substantial, the few existing data are used and patterns are searched to generate additional data
– no data are available at all, simulation techniques can be used to generate data sets
The potential applications in a wide variety of fields are enormous: from quality control of products, to production of different products in an existing manufacturing facility, to image-based diagnosis of colon cancer regions.
Which methods are used in which application and what Few Data Learning has to do with Few Labels Learning, Christian reveals in the new episode!


