Optimierung von Prozessen durch Interaktionen mit der Umwelt
In der hier angekündigten Podcastfolge spreche ich wieder mit Dr. Ing. Christopher Mutschler, der bereits für die Folge »Sequenzbasiertes Lernen« mein Gast war. Diesmal erfahren wir von ihm, was in der Kompetenzsäule »Erfahrungsbasiertes Lernen« des ADA Lovelace Center genau erforscht wird.
Was beim Erfahrungsbasierten Lernen besonders spannend ist: Hier geht es nicht um ein Modell, das mit annotierten oder nicht annotierten Daten gefüttert wird, und anhand dieser Daten immer präzisere Voraussagen trifft oder lernt. Sondern das KI-System sammelt durch direkte Interaktion mit seiner Umwelt Daten, die es dann mit bestehenden Modellen verknüpft, oder selbstständig neue Modelle für die Optimierung seines Verhaltens dazulernt.
Das heißt, das KI-System ist selber dafür zuständig, die richtigen Daten zu sammeln und zu verarbeiten. Dadurch ergeben sich natürlich Herausforderungen: der Agent des KI-Systems nimmt durch die direkte Interaktion mit der Umwelt auch Einfluss auf diese. Erfahrungsbasiertes Lernen umfasst eine Vielzahl von Methoden, die es einem Agenten ermöglichen, anhand von Interaktion mit der Umwelt und dem Feedback der Umwelt zu lernen – also anhand von Erfahrung.
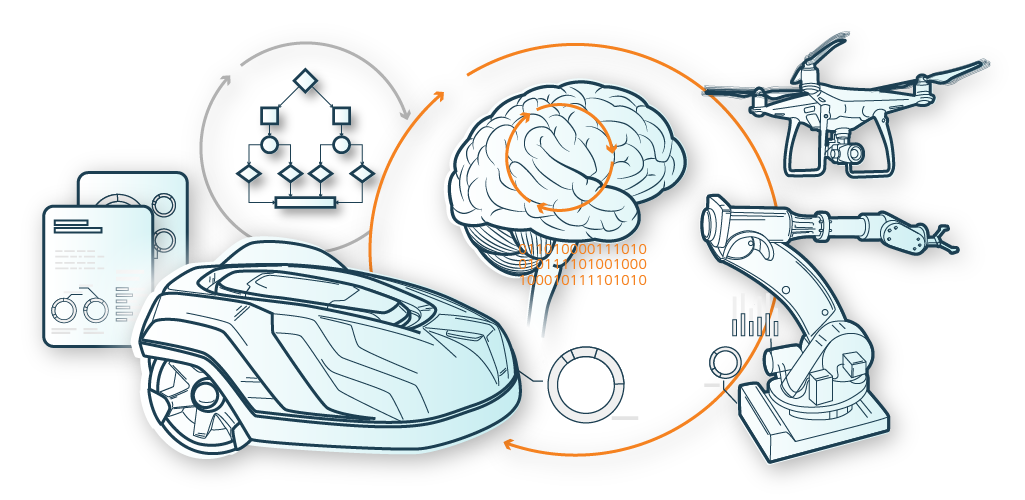
Ein simples Beispiel dafür ist ein Mähroboter, der auch automatisch lernt, den Rasen optimal zu düngen. Er merkt sich, wann er wo wieviel Gras geschnitten und wieviel Dünger ausgebracht hat. In einer Belohnungsfunktion wird definiert, wie gut zum Beispiel das Rasenwachstum in einer bestimmten Zeit sein soll bei einem möglichst geringen Düngereinsatz. Der Rasenmähroboter sammelt somit indirekt Erfahrung über die Bodenbeschaffenheit, interagiert auch mit der Umwelt (mäht und düngt) und versucht sich mit seiner Düngung an den richtigen Bedarf anzunähern.
Wichtige Fragen in dieser Kompetenzsäule sind daher:
- Wie häufig muss der Agent mit der Umwelt interagieren bis er gelernt hat, wie er sich zu verhalten hat?
- Welches Verhalten des Agenten in der jeweiligen Umwelt ist richtig bzw. erwünscht?
Dabei ist eine weitere Herausforderung, dass die Interaktion mit der Umwelt oftmals keinen direkten erwünschten Effekt erbringt, sondern mit Zeitverzögerung, dem sogenannten Delayed Reward. Was das ist, warum das eine Herausforderung für den Agenten ist und vieles mehr erfahren Sie im Podcast. Viel Spaß beim Hören!
Experience-based learning
Optimizing processes through interactions with the environment
In this podcast episode I talk again with Dr. Ing. Christopher Mutschler, who was already my guest for the episode “Sequence-based Learning”. In this episode, he shares what exactly is being researched in the “Experience-based learning” competency pillar at the ADA Lovelace Center.
What’s particularly exciting about experience-based learning is that it’s not about a model that is trained with annotated or unannotated data and uses that data to make increasingly accurate predictions or learn. Instead, the AI system collects data through direct interaction with its environment, which it then combines with existing models or independently learns new models to optimize its behavior.
In other words, the AI system itself is responsible for collecting the right data. This, of course, creates challenges because the AI system, or the so called agent, interacts directly with the environment and also influences it. Experience-based learning involves a variety of methods that allow an agent to learn based on interaction with the environment and feedback from the environment – in other words, based on experience.
A simple example is a robotic lawnmower that also automatically learns how to fertilize the lawn optimally. It remembers when and where it cut how much grass and how much fertilizer it applied. A reward function defines how good the lawn growth should be in a certain period of time with the lowest possible fertilizer application. The robotic lawnmower indirectly gains experience about soil conditions, also interacts with the environment (mows and fertilizes), and tries to approximate the correct requirements with its fertilization.
Important questions in this competence pillar are therefore:
How often does the agent need to interact with the environment until it learns how to behave?
Which behavior of the agent in the respective environment is correct or desired?
That is another challenge. The interaction with the environment often does not yield a direct desired effect, but rather with a time delay, the so-called delayed reward. Find out what this is, why it’s a challenge for the agent, and much more in the podcast. Enjoy listening!